En mineria de datos, k -means es un método de agrupamiento, que tiene como objetivo la [partición [de un conjunto]] n en k grupos en el que cada observación pertenece al grupo más cercano a la media. Esto da lugar a una compartimentación del espacio de datos en celdas de Voronoi.
El problema es computacionalmente difícil (NP-hard). Sin embargo, hay eficientes heurísticas que se emplean comúnmente y convergen rápidamente a un óptimo local. Estos suelen ser similares a los algoritmos expectation-maximization de mezclas de distribuciones gausianas
por medio de un enfoque de refinamiento iterativo empleado por ambos
algoritmos. Además, los dos algoritmos usan los centros que los grupos
utilizan para modelar los datos, sin embargo k-means tiende a
encontrar grupos de extensión espacial comparable, mientras que el
mecanismo expectation-maximization permite que los grupos que tengan
formas diferentes.
Descripción
Dado un conjunto de observaciones (x1, x2, …, xn), donde cada observación es un vector real de d dimensiones, k-means construye una partición de las observaciones en k conjuntos (k = n) S = {S1, S2, …, Sk}a fin de minimizar la suma de los cuadrados dentro de cada grupo (WCSS):

Historia
El término "k-means" fue utilizado por primera vez por James MacQueen en 1967,aunque la idea se remonta a Hugo Steinhaus en 1957. El [algoritmo [# Standard | algoritmo estándar]] fue propuesto por primera vez por Stuart Lloyd en 1957 como una técnica para modulación por impulsos codificados, aunque no se publicó fuera de los laboratorios Bell hasta 1982. En 1965, E. W. Forgy publicó esencialmente el mismo método, por lo que a veces también se le nombra como Lloyd-Forgy. Una versión más eficiente fue propuesta y publicada en Fortran por Hartigan y Wong en 1975/1979.Algoritmos
Algoritmo estándar
El algoritmo más común utiliza una técnica de refinamiento iterativo. Debido a su ubicuidad a menudo se llama el algoritmo k-means', también se le conoce como 'algoritmo de Lloyd, sobre todo en la comunidad informática.Dado un conjunto inicial de k centroides m1(1),…,mk(1)
(ver más abajo), el algoritmo continúa alternando entre dos pasos:7
- Paso de asignación: Asigna cada observación al grupo con la media
-

- Donde cada
 va exactamente dentro de un
va exactamente dentro de un
 , incluso aunque pudiera ir en dos de ellos.
, incluso aunque pudiera ir en dos de ellos.- Paso de actualización: Calcular los nuevos centroides como el centroide de las observaciones en el grupo.

Comúnmente utilizados son los métodos de inicialización de Forgy y Partición Aleatoria. El método Forgy elige aleatoriamente k observaciones del conjunto de datos y las utiliza como centroides iniciales. El método de partición aleatoria primero asigna aleatoriamente un clúster para cada observación y después procede a la etapa de actualización, por lo tanto calcular el cluster inicial para ser el centro de gravedad de los puntos de la agrupación asignados al azar. El método Forgy tiende a dispersar los centroides iniciales, mientras que la partición aleatoria ubica los centroides cerca del centro del conjunto de datos. Según Hamerly y compañia, el método de partición aleatoria general, es preferible para los algoritmos tales como los k-harmonic means y fuzzy k-means. Para expectation maximization y el algoritmo estandar el método de Forgy es preferible.
- Demonstración del algoritmos estandar
-
 1) k centroides iniciales (en este caso k=3)
1) k centroides iniciales (en este caso k=3) -
Son generados aleatoriamente dentro de un conjunto de datos (mostrados en color).
-
 2) k grupos son generados asociandole el punto
2) k grupos son generados asociandole el punto -
 3) EL centroide de cada uno de los k grupos se recalcula.
3) EL centroide de cada uno de los k grupos se recalcula. -
 4) Pasos 2 y 3 se repiten hasta que se logre la convergencia.
4) Pasos 2 y 3 se repiten hasta que se logre la convergencia.
El "paso de asignación" también se le conoce como paso expectativa, la "etapa de actualización", como paso maximización, por lo que este algoritmo una variante del algoritmo generalizado expectation-maximization.
Complejidad
Respecto a la complejidad computacional, el agrupamiento k-means para problemas en espacios de d dimensiones es:- NP-hard en un espacio euclideano general d incluso para 2 grupos
- NP-hard para un numero general de grupos k incluso en el plano
- Si k y d son fijados, el problema se puede resolver en un tiempo
O(ndk+1 log n), donde n es el numero de entidades a particionar
Por lo tanto, una gran variedad de heuristicas son usadas generalmente.
- El algoritmo
 -means que se discute debajo tiene
-means que se discute debajo tiene
 puntos en
puntos en ![[0,1]^d](https://upload.wikimedia.org/math/2/6/b/26bc47a1ae7c57f9c370dd5928d898a4.png) , si cada punto es perturbado independientemente por una distribución normal con media
, si cada punto es perturbado independientemente por una distribución normal con media  y varianza
y varianza  , entonces el tiempo de corrida del algoritmo -means esta acotado por
, entonces el tiempo de corrida del algoritmo -means esta acotado por 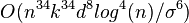 , que es un tiempo polinomial en , ,
, que es un tiempo polinomial en , ,  y
y 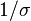 .
.- Se han demostrado mejores cotas para casos simples. Por
-means esta acotado por 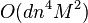 para puntos enteros en la rejilla
para puntos enteros en la rejilla 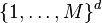 .
.Variaciones
- Fuzzy C-Means Clustering es una versión difusa del K-means,
- Modelos de mezclas gausianas entrenadas con el algoritmo expectation-maximization presentan
- Se han presentado varios métodos para elegir mejor los centroides iniciales. Una propuesta reciente es k-means++.
- Algoritmos de filtrado utilizan kd-trees para mejorar la eficiencia en cada paso del algoritmo.
- Algunos métodos también intentan acelerar el algoritmo usando coresets.
or the triangle inequality.
- Se puede escapar de óptimos locales intercambiando puntos entre los grupos.
- El algoritmo Spherical k-means es bastante usado para datos direccionales.
- EL algoritmo Minkowski metric weighted k-means trata el problema
Discusión



- La distancia euclideana se usa como una métrica y la varianza es usada como una medida de la dispersión de los grupos.
- El número de grupos k es un parámetro de entrada: una elección inapropiada puede acarrear malos resultados. Por eso es muy importante cuando corremos el k-means tener en cuenta la importancia de determinar el numeros de grupos para un conjunto de datos.
- La convergencia a óptimos locales puede traer malos resultados(ver ejemplo en Fig.).
 al conjunto de datos Iris flower, el resultado no es el esperado incluso habiendo tres especies en el conjunto de datos. Con
al conjunto de datos Iris flower, el resultado no es el esperado incluso habiendo tres especies en el conjunto de datos. Con 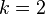 , los dos grupos visibles(uno conteniendo dos especies) se pueden observar, mientras que con uno de los dos grupos se divide en dos partes iguales. De hecho, es más apropiado para este conjunto de datos, aunque este último contenga 3 clases. Como con cualquier otro algoritmo de agrupamiento, el resultado de k-means
depende del conjunto de datos para satisfacer las necesidades del
algoritmo. Simplemente trabaja bien en algunos conjuntos de datos
mientras que falla en otros.
, los dos grupos visibles(uno conteniendo dos especies) se pueden observar, mientras que con uno de los dos grupos se divide en dos partes iguales. De hecho, es más apropiado para este conjunto de datos, aunque este último contenga 3 clases. Como con cualquier otro algoritmo de agrupamiento, el resultado de k-means
depende del conjunto de datos para satisfacer las necesidades del
algoritmo. Simplemente trabaja bien en algunos conjuntos de datos
mientras que falla en otros.El resultado del k-means se puede ver como las celdas de Voronoi de los centroides de los grupos. Como los datos se separan en cierta forma por la media de los grupos, esto puede llevarnos a óptimos locales como se puede ver en la colleccion "mouse". Los modelos gausianos usados por el algoritmo Expectation-maximization (que puede ser visto como una
generalización del k-means) son más flexibles ya que controlanvarianzas y covarianzas. El resultado de EM crea grupos con tamaño variable más fácilmente que k-means tanto como grupos correlacionados (no en este ejemplo).
Applicaciones del algoritmo
Agrupamiento k-means cuando se usan heurísticas como el algiritmo de Lloyd es fácil de implementar incluso para largos conjuntos de datos. Por lo que ha sido ampliamente usado en muchas areas como segmentación de mercados, visión por computadoras, geoestadística, and astronomy to [[Data Mining in Agriculture|agriculture]]. También se usa como preprocesamiento para otros algoritmos, por ejemplo para buscar una configuración inicial.Software
Libre
- Apache Mahout k-Means
- CrimeStat implemanta dos algoritmos espaciales de k-means, uno de ellos permite al usuario definir los puntos iniciales.
- ELKI contiene k-means (con iteracionesd de Lloyd and MacQueen, as'i como diferente inicializaciones, por ejemplo k-means++) y otros algoritmos de agrupamientos más avanzados.
- MLPACK contiene una implementación del k-means
- R kmeans implementa una variedad de algoritmos
- SciPy vector-quantization
- Silverlight widget mostrando el algoritmo k-means
- extensiones PostgreSQL para k-means
- CMU's GraphLab Clustering library Implementacion eficiente para varios processadores.
- Weka contiene k-means y algunas varientes, como k-means++ y x-means.
- Spectral Python contiene metodos para la clasificación no supervisada incluyendo el algoritmo k-means.
Comercial
- IDL Cluster, Clust_Wts
- Mathematica ClusteringComponents function
- MATLAB kmeans
- SAS FASTCLUS
- VisuMap kMeans Clustering
Código fuente
- ELKI and Weka esta escrito en Java y contiene implementaciones del k-means
- K-means en PHP, using VB, using Perl, using C++, using Matlab, using Ruby, using Python with scipy, using X10
- Una implementación en C
- Una colección de algoritmos de agrupamientos incluido k-means, implementado en Javascript.33 Online demo.










