La propagación hacia atrás de errores o retropropagación (del inglés backpropagation) es un algoritmo de aprendizaje supervisado que se usa para entrenar redes neuronales artificiales. El algoritmo emplea un ciclo propagación – adaptación de dos fases. Una vez que se ha aplicado un patrón a la entrada de la red como estímulo, este se propaga desde la primera capa a través de las capas superiores de la red, hasta generar una salida.
La señal de salida se compara con la salida deseada y se calcula una señal de error para cada una de las salidas. Las salidas de error se propagan hacia atrás, partiendo de la capa de salida, hacia todas las neuronas de la capa oculta que contribuyen directamente a la salida. Sin embargo las neuronas de la capa oculta solo reciben una fracción de la señal total del error, basándose aproximadamente en la contribución relativa que haya aportado cada neurona a la salida original. Este proceso se repite, capa por capa, hasta que todas las neuronas de la red hayan recibido una señal de error que describa su contribución relativa al error total. La importancia de este proceso consiste en que, a medida que se entrena la red, las neuronas de las capas intermedias se organizan a sí mismas de tal modo que las distintas neuronas aprenden a reconocer distintas características del espacio total de entrada. Después del entrenamiento, cuando se les presente un patrón arbitrario de entrada que contenga ruido o que esté incompleto, las neuronas de la capa oculta de la red responderán con una salida activa si la nueva entrada contiene un patrón que se asemeje a aquella característica que las neuronas individuales hayan aprendido a reconocer durante su entrenamiento.
Estructura del Perceptrón
El modelo de una neurona artificial es una imitación del proceso de una neurona biológicaDonde los
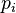 son las entradas (por las dendritas) a la neurona, estas sufren un efecto multiplicador
son las entradas (por las dendritas) a la neurona, estas sufren un efecto multiplicador 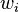 por la comunicación de las mismas al núcleo de la neurona, donde se sumaran mediante:
por la comunicación de las mismas al núcleo de la neurona, donde se sumaran mediante:
La salida de la neurona luego es modificada mediante la función de transferencia f:

Perceptrón Multicapa
Un Perceptrón multicapa es una red con alimentación hacia delante, compuesta de varias capas de neuronas entre la entrada y la salida de la misma, esta red permite establecer regiones de decisión mucho más complejas que las de dos semiplanos, como lo hace el Perceptrón de un solo nivel. Las capacidades del Perceptrón multicapa con dos y tres capas y con una única neurona en la capa de salida se muestran en la siguiente figura:
Perceptrón simple, activándose su salida para los patrones de un lado del hiperplano, si el valor de los pesos de las conexiones entre las neuronas de la segunda capa y una neurona del nivel de salida son todos igual a 1, y la función de salida es de tipo hardlim, la salida de la red se activará sólo si las salidas de todos los nodos de la segunda capa están activos, esto equivale a ejecutar la función lógica AND en el nodo de salida, resultando una región de decisión intersección de todos los semiplanos formados en el nivel anterior. La región de decisión resultante de la intersección será una región convexa con un número de lados a lo sumo igual al número de neuronas de la segunda capa. A partir de este análisis surge el interrogante respecto a los criterios de selección para las neuronas de las capas ocultas de una red multicapa, este número en general debe ser lo suficientemente grande como para que se forme una región compleja que pueda resolver el problema, sin embargo no debe ser muy grande pues la estimación de los pesos puede ser no confiable para el conjunto de los patrones de entrada disponibles. Hasta el momento no hay un criterio establecido para determinar la configuración de la red y esto depende más bien de la experiencia del diseñador.
Estructura de la Red
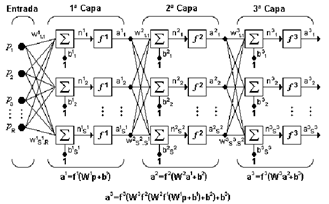
Puede notarse que esta red de tres capas equivale a tener tres redes tipo Perceptrón en cascada; la salida de la primera red, es la entrada a la segunda y la salida de la segunda red es la entrada a la tercera. Cada capa puede tener diferente número de neuronas, e incluso distinta función de transferencia.
Regla de Aprendizaje
La red Backpropagation trabaja bajo aprendizaje supervisado y por tanto necesita un set de entrenamiento que le describa cada salida y su valor de salida esperado de la siguiente forma:
Donde
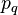 es una entrada a la red y
es una entrada a la red y  es la correspondiente salida deseada para el patrón q-ésimo. El
algoritmo debe ajustar los parámetros de la red para minimizar el error
cuadrático medio. Es importante recalcar que no existe una técnica para
determinar el número de capas ocultas, ni el número de neuronas que debe
contener cada una de ellas para un problema especifico, esta elección
es determinada por la experiencia del diseñador, el cual debe cumplir
con las limitaciones de tipo computacional. Cada patrón de entrenamiento
se propaga a través de la red y sus parámetros para producir una
respuesta en la capa de salida, la cual se compara con los patrones
objetivo o salidas deseadas para calcular el error en el aprendizaje,
este error marca el camino mas adecuado para la actualización de los
pesos y ganancias que al final del entrenamiento producirán una
respuesta satisfactoria a todos los patrones de entrenamiento, esto se
logra minimizando el error cuadrático medio en cada iteración del
proceso de aprendizaje.
es la correspondiente salida deseada para el patrón q-ésimo. El
algoritmo debe ajustar los parámetros de la red para minimizar el error
cuadrático medio. Es importante recalcar que no existe una técnica para
determinar el número de capas ocultas, ni el número de neuronas que debe
contener cada una de ellas para un problema especifico, esta elección
es determinada por la experiencia del diseñador, el cual debe cumplir
con las limitaciones de tipo computacional. Cada patrón de entrenamiento
se propaga a través de la red y sus parámetros para producir una
respuesta en la capa de salida, la cual se compara con los patrones
objetivo o salidas deseadas para calcular el error en el aprendizaje,
este error marca el camino mas adecuado para la actualización de los
pesos y ganancias que al final del entrenamiento producirán una
respuesta satisfactoria a todos los patrones de entrenamiento, esto se
logra minimizando el error cuadrático medio en cada iteración del
proceso de aprendizaje.
q: Núm.de componentes del vector de entrada.
m: Número de neuronas de la capa oculta.
l: Número de neuronas de la capa de salida.
Para iniciar el entrenamiento se le presenta a la red un patrón de
entrenamiento, el cual tiene q componentes como se describe en la
ecuación (2):
Cuando se le presenta a la red un patrón de entrenamiento, este se propaga a través de las conexiones existentes produciendo una entrada neta n en cada una las neuronas de la siguiente capa, la entrada neta a la neurona j de la siguiente capa debido a la presencia de un patrón de entrenamiento en la entrada está dada por la ecuación (3), nótese que la entrada neta es el valor justo antes de pasar por la función de transferencia:

 :Peso que une la componente i de la entrada con la neurona j de la capa oculta.
:Componente i del vector p que conteiene el patrón de entrenamiento de q componentes.
:Peso que une la componente i de la entrada con la neurona j de la capa oculta.
:Componente i del vector p que conteiene el patrón de entrenamiento de q componentes.
 :Ganancia de la neurona j de la capa oculta.
:Ganancia de la neurona j de la capa oculta.
Donde (0) representa la capa a la que pertenece cada parámetro, es
este caso la capa oculta. Cada una de las neuronas de la capa oculta
tiene como salida  , dada por:
, dada por:
 : Función de transferencia de las neuronas de la capa oculta. Las salidas
de las neuronas de la capa oculta (de m componentes) son las entradas a
los pesos de conexión de la capa de salida, este comportamiento esta
descripto por:
: Función de transferencia de las neuronas de la capa oculta. Las salidas
de las neuronas de la capa oculta (de m componentes) son las entradas a
los pesos de conexión de la capa de salida, este comportamiento esta
descripto por:
 : Peso que une la neurona j de la capa oculta con la neurona k de la capa de salida, la cual cuenta con s neuronas.
: Salida de la neurona j de la capa oculta, la cual cuenta con m neuronas.
: Peso que une la neurona j de la capa oculta con la neurona k de la capa de salida, la cual cuenta con s neuronas.
: Salida de la neurona j de la capa oculta, la cual cuenta con m neuronas.
 : Ganancia de la neurona k de la capa de salida.
: Ganancia de la neurona k de la capa de salida.
 : Entrada neta a la neurona k de la capa de salida.
: Entrada neta a la neurona k de la capa de salida.
La red produce una salida final: 
 : Función de transferencia de las neuronas de la capa de salida.
: Función de transferencia de las neuronas de la capa de salida.La salida de la red de cada neurona
 se compara con la salida deseada
se compara con la salida deseada  para calcular el error en cada unidad:
para calcular el error en cada unidad: 
El error debido a cada patrón p propagado está dado por:

 : Error cuadrático medio para cada patrón de entrada p.
: Error cuadrático medio para cada patrón de entrada p. : Error en la neurona k de la capa de salida con l neuronas.
: Error en la neurona k de la capa de salida con l neuronas.Este proceso se repite para el número total de patrones de entrenamiento (r), para un proceso de aprendizaje exitoso el objetivo del algoritmo es actualizar todos los pesos y ganancias de la red minimizando el error cuadrático medio total descrito en:

 :
Error total en el proceso de aprendizaje en una iteración luego de
haber presentado a la red los r patrones de entrenamiento. El error que
genera una red neuronal en función de sus pesos, genera un espacio de n
dimensiones, donde n es el número de pesos de conexión de la red, al
evaluar el gradiente del error en un punto de esta superficie se
obtendrá la dirección en la cual la función del error tendrá un mayor
crecimiento, como el objetivo del proceso de aprendizaje es minimizar el
error
:
Error total en el proceso de aprendizaje en una iteración luego de
haber presentado a la red los r patrones de entrenamiento. El error que
genera una red neuronal en función de sus pesos, genera un espacio de n
dimensiones, donde n es el número de pesos de conexión de la red, al
evaluar el gradiente del error en un punto de esta superficie se
obtendrá la dirección en la cual la función del error tendrá un mayor
crecimiento, como el objetivo del proceso de aprendizaje es minimizar el
errordebe tomarse la dirección negativa del gradiente para obtener el mayor decremento del error y de esta forma su minimización, condición requerida para realizar la actualización de la matriz de pesos en el algoritmo Backpropagation:
(Continua)
Minimización del Error
Los algoritmos en Aprendizaje Automático pueden ser clasificados en dos categorías: supervisados y no supervisados. Los algoritmos en aprendizaje supervisado son usados para construir "modelos" que generalmente predicen ciertos valores deseados. Para ello, los algoritmos supervisados requieren que se especifiquen los valores de salida (output) u objetivo (target) que se asocian a ciertos valores de entrada (input). Ejemplos de objetivos pueden ser valores que indican éxito/fallo, venta/no-venta, pérdida/ganancia, o bien ciertos atributos multi-clase como cierta gama de colores o las letras del alfabeto. El conocer los valores de salida deseados permite determinar la calidad de la aproximación del modelo obtenido por el algoritmo.La especificación de los valores entrada/salida se realiza con un conjunto consistente en pares de vectores con entradas reales de la forma
 , conocido como conjunto de entrenamiento o conjunto de ejemplos, donde
, conocido como conjunto de entrenamiento o conjunto de ejemplos, donde 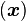 serán nuestros parámetros de entrada y
serán nuestros parámetros de entrada y  los de salida de la red. Los algoritmos de aprendizaje generalmente calculan los parámetros
los de salida de la red. Los algoritmos de aprendizaje generalmente calculan los parámetros 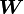 de una función
de una función  que permiten aproximar los valores de salida en el conjunto de entrenamiento.
que permiten aproximar los valores de salida en el conjunto de entrenamiento.Si
 ,
,  , son los elementos del conjunto de entrenamiento, la calidad de la aproximación en el ejemplo
, son los elementos del conjunto de entrenamiento, la calidad de la aproximación en el ejemplo  se puede medir a través del error cuadrático:
se puede medir a través del error cuadrático: ,
,donde
 es la norma euclidiana.
es la norma euclidiana.El error total es la suma de los errores de los ejemplos:
 .
.Un método general para minimizar el error es el actualizar los parámeros de manera iterativa. El valor nuevo de los parámetros se calcula al sumar un incremento
 al valor actual:
al valor actual:
El algoritmo se detiene cuando
converge o bien cuado el error alcanza un mínimo valor deseado.Si la función
usada para aproximar los valores de salida es diferenciable respecto a los parámetros ,
podemos usar como algoritmo de aprendijaze el método de gradiende
descendiente. En este caso, el incremento de los parámetros se expresa
como
donde
 es un parámetro conocido como factor de aprendizaje.
es un parámetro conocido como factor de aprendizaje.Antes de continuar introduciremos un poco de notación. Definimos
 como el vector extendido del vector
como el vector extendido del vector  . El par representará a un elemento del conjunto de entrenamiento y una relación de entrada-salida, a menos que se indique otra cosa.
. El par representará a un elemento del conjunto de entrenamiento y una relación de entrada-salida, a menos que se indique otra cosa.Red Neuronal con una Capa Oculta
La función la usaremos para aproximar los valores de salida de una red neuronal artificial con una capa oculta. La red está constituida por una capa de entrada (input layer), una capa oculta (hidden layer) y una capa de salida (output layer), tal como se ilustra con la siguiente figura: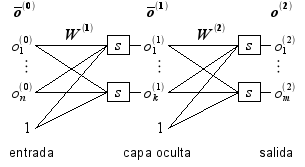
Los elementos que constituyen la red neuronal son los siguientes:
 es una función de valores reales, conocida como la función de transferencia.
es una función de valores reales, conocida como la función de transferencia.
 es la capa de entrada, considerado como el vector extendido del ejemplo
es la capa de entrada, considerado como el vector extendido del ejemplo  .
.
 es la capa oculta, el vector extendido de
es la capa oculta, el vector extendido de  .
.
 es la capa de salida, considerado como el vector que aproxima al valor deseado
es la capa de salida, considerado como el vector que aproxima al valor deseado  .
.
 es una matriz de tamaño
es una matriz de tamaño  cuyos valores
cuyos valores  son los pesos de la conexión entre las unidades
son los pesos de la conexión entre las unidades  y
y  .
.
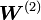 es una matriz de tamaño
es una matriz de tamaño  cuyos valores
cuyos valores  son los pesos de la conexión entre las unidades
son los pesos de la conexión entre las unidades  y
y  .
.
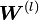 son consideradas como los parámetros de la red, ya que los valores
son consideradas como los parámetros de la red, ya que los valores  son el resultado de cálculos que dependen de las matrices de pesos, del valor de entrada
son el resultado de cálculos que dependen de las matrices de pesos, del valor de entrada  y de la función de transferencia .
y de la función de transferencia .La función de transferencia
que consideraremos en nuestro algoritmo es conocida como función sigmoidal, y esta definida como
esta función además de ser diferenciable, tiene la particularidad de que su derivada se puede expresar en términos de sí misma:

esto nos servirá para simplificar los cálculos en el algoritmo de aprendizaje aquí descrito.
Descripción del Algoritmo
A grandes rasgos:- Calcular la salida de la red
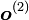 a partir de uno de los conjuntos de valores de prueba
a partir de uno de los conjuntos de valores de prueba  .
. - Comparar con la salida correcta
 y calcular el error según la fórmula:
y calcular el error según la fórmula:
- Calcular las derivadas parciales del error con respecto a los pesos que unen a la última capa oculta con la de salida.
- Calcular las derivadas parciales del error con respecto a los pesos que unen la capa de entrada con la oculta.
- Ajustar los pesos de cada neurona para reducir el error.
- Repetir el proceso varias veces por cada par de entradas-salidas de prueba.
